Huffman Encoding vs Fixed Length Encoding
Huffman Encoding:
Jadi, Huffman encoding itu semacam cara buat ngecilin ukuran data, gitu. Intinya, dia bikin kode yang lebih pendek buat karakter yang sering muncul dan kode yang lebih panjang buat yang jarang muncul. Jadi, kita bisa menghemat ruang penyimpanan atau mengurangi waktu saat data itu dikirim. Dengan cara ini, kita bisa bikin data lebih efisien tanpa nambah-nambahin ukuran yang nggak perlu.
Memahami Cara Kerja Huffman Encoding:
- Cek Berapa Sering Karakter Muncul: Pertama-tama, kita hitung seberapa sering tiap karakter muncul di data yang mau kita kompres. Bayangkan kayak lagi ngitung berapa banyak biskuit yang ada di toples!
- Bikin Pohon Huffman: Setelah itu, kita bikin yang namanya pohon biner. Di sini, setiap daun pohon itu mewakili karakter. Kita mulai dari yang frekuensinya paling rendah dan gabungin mereka satu per satu sampai semua karakter jadi satu pohon yang kompak.
- Tentukan Kode untuk Karakter: Selanjutnya, kita jalan dari akar pohon ke daun, dan sambil jalan kita tentukan kode biner untuk setiap karakter. Kalau kita ke kiri, kasih ‘0’, dan ke kanan kasih ‘1’.
- Kompres Data: Terakhir, kita ganti setiap karakter di data asli dengan kode biner yang udah kita buat. Jadi, data kita sekarang lebih ringkas dan siap untuk disimpan atau dikirim.
Kelebihan Huffman Encoding:
- Efisien: Dengan cara ini, kita bisa menghemat jumlah bit yang dipakai, jadi lebih hemat dibanding cara biasa yang panjangnya tetap.
- Adaptif: Panjang kode bisa nyesuaiin sendiri, tergantung seberapa sering karakter itu muncul.
Fixed-Length Encoding:
Jadi, fixed-length encoding itu kayak cara ngodein karakter atau simbol dengan kode yang panjangnya sama, nggak peduli seberapa sering karakter itu muncul. Contoh gampangnya adalah pengkodean ASCII, di mana setiap karakter diwakili oleh 8 bit. Jadi, semua karakter dapet jatah kode yang sama, meskipun ada yang lebih sering dipakai.
Kelemahan Fixed-Length Encoding:
- Kurang Efisien: Metode ini nggak bisa memanfaatkan seberapa sering sebuah karakter muncul. Jadi, misalnya karakter yang jarang muncul tetap makan jumlah bit yang sama dengan karakter yang sering muncul.
- Ukuran Data Tidak Berkurang Signifikan: Semua karakter dapat kode dengan panjang yang sama, jadi kompresinya nggak sebagus metode lain, seperti Huffman encoding yang lebih pintar ngatur panjang kode sesuai frekuensi kemunculan.
Uji Coba
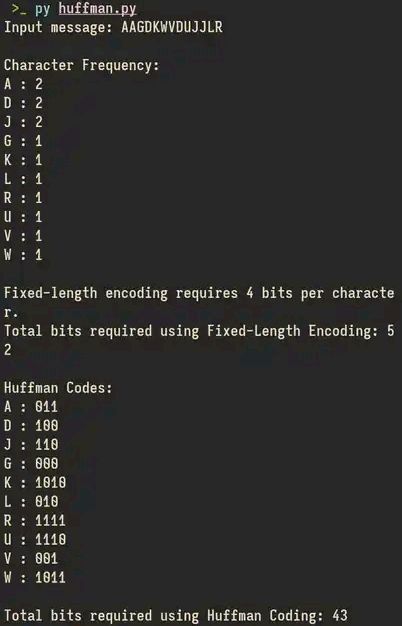
Kesimpulan:
Di gambar di atas itu contoh perbandingan antara Huffman Encoding dan Fixed-Length Encoding dimana hasilnya total bit pada Huffman Encoding lebih sedikit dibanding Fixed-Length Encoding.
Jadi, Huffman encoding itu adalah cara kompresi yang lebih cerdas karena menggunakan panjang yang bervariasi, jadi lebih efisien daripada encoding dengan Fixed-Length Encoding. Ini terutama berguna saat data kita punya variasi frekuensi yang cukup mencolok antar karakter. Pilihan antara dua metode ini tergantung sama apa yang kamu butuhkan dan karakteristik data yang mau dikompresi.